 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Diagnostics of Spatial Lexical Bias in Multimodal Large Language Model Spatial Reasoning
Jun 01, 2026Multimodal large language models (MLLMs) remain unreliable on spatial multiple-choice questions, and their failures are often attributed to poorly attended visual information. In this work, we identify a complementary failure mode, spatial lexical bias: adding a spatial relation word to the answer options can attract the model's decision and make the newly added option likely to be selected. Using nine open-weight MLLMs, we show that this phenomenon is widely observed. In particular, models can answer a binary spatial question correctly, yet consistently select an incorrect third spatial option once it is added to the answer set. We isolate such binary-stable but ternary-fragile cases as diagnostic examples and leverage mechanistic interpretability tools, revealing that a substantial part of the failure instead originates on the language side rather than the visual side: visual attention analyses and residual-stream probes show the correct spatial relation remains internally available on these failures, while irrelevant-option controls, activation patching, and sparse component interventions trace the bias to specific LLM-side channels and neurons. Based on this finding, we show that a lightweight LLM-only DPO update on tiny single-object-pair synthetic data mitigates the bias, lifting four-way robust accuracy by up to 100 points on synthetic data, and by 68.0, 32.6, and 20.1 points on broader evaluation datasets WhatsUp, SpatialMQA-Direct, and VSR.
Not All Flips Are Conformity: Decomposing Stance Convergence in Multi-Agent LLM Debate
May 30, 2026Multi-agent debate (MAD) is a promising strategy for improving LLM reasoning, but when agents converge on a shared answer, it is unclear whether that convergence reflects genuine deliberation or social compliance. We show that the conventional answer flip rate conflates three distinct mechanisms: spontaneous instability, stance-induced conformity, and reasoning-induced persuasion. Our three-source decomposition framework isolates each through controlled counterfactual conditions. In the primary MMLU-Pro setting, 37% of agent-question observations change under self-reflection alone, while robustness tests show substantial model-dependent instability across GPQA-Diamond and three model families; strict conformity is 29% in the primary setting and remains predominantly harmful across model replications (57-77% correct-to-wrong). A controlled information-gradient experiment reveals that even vacuous reasoning is associated with 20-39% error adoption among resistant agents, with reasoning-like presentation carrying substantial persuasive weight. Harmful conformity can be predicted from Round 0 features (AUC = 0.79), and risk-targeted intervention reduces it by 13.6 percentage points (p < 0.001). However, without correctness labels or self-reflection controls, reducing peer adoption does not improve accuracy, because harmful and beneficial influence cannot be distinguished.
The Cases LJP Never Sees: Prosecution Decision Prediction for More Complete Criminal Liability Assessment
May 27, 2026Legal Judgment Prediction (LJP) has become a core benchmark for evaluating AI in the criminal legal domain, but it only sees criminal cases that have already passed prosecutorial review and been formally indicted. As a result, LJP leaves a substantial blind spot in assessing criminal liability, overlooking cases involving insufficient evidence, no criminal liability, or guilt exempted from punishment. To fill this gap, we propose \textbf{Prosecution Decision Prediction (PDP)}, the first Legal AI task built around prosecutorial review, which classifies each case into prosecution or one of three non-prosecution decisions and reflects legal AI's capabilities in evidence evaluation, legal subsumption, and value-based discretion. We further construct \textbf{PDP-Bench}, a benchmark of 4{,}630 real Chinese prosecutorial decisions spanning 190 charges. Extensive experiments show that state-of-the-art LLMs perform substantially worse on PDP than on LJP and that mainstream enhancement routes fail to close the gap. Moreover, controlled RLVR interventions show that simple outcome rewards fail to produce generalizable PDP discrimination.
ShapleyLaw: A Game-Theoretic Approach to Multilingual Scaling Laws
Mar 18, 2026In multilingual pretraining, the test loss of a pretrained model is heavily influenced by the proportion of each language in the pretraining data, namely the \textit{language mixture ratios}. Multilingual scaling laws can predict the test loss under different language mixture ratios and can therefore be used to estimate the optimal ratios. However, the current approaches to multilingual scaling laws do not measure the \textit{cross-lingual transfer} effect, resulting in suboptimal mixture ratios. In this paper, we consider multilingual pretraining as a cooperative game in which each language acts as a player that jointly contributes to pretraining, gaining the resulting reduction in test loss as the payoff. Consequently, from the perspective of cooperative game theory, we quantify the cross-lingual transfer from each language by its contribution in the game, and propose a game-theoretic multilingual scaling law called \textit{ShapleyLaw}. Our experiments show that ShapleyLaw outperforms baseline methods in model performance prediction and language mixture optimization.
Seven Security Challenges That Must be Solved in Cross-domain Multi-agent LLM Systems
May 28, 2025

Large language models (LLMs) are rapidly evolving into autonomous agents that cooperate across organizational boundaries, enabling joint disaster response, supply-chain optimization, and other tasks that demand decentralized expertise without surrendering data ownership. Yet, cross-domain collaboration shatters the unified trust assumptions behind current alignment and containment techniques. An agent benign in isolation may, when receiving messages from an untrusted peer, leak secrets or violate policy, producing risks driven by emergent multi-agent dynamics rather than classical software bugs. This position paper maps the security agenda for cross-domain multi-agent LLM systems. We introduce seven categories of novel security challenges, for each of which we also present plausible attacks, security evaluation metrics, and future research guidelines.
Text-IRSTD: Leveraging Semantic Text to Promote Infrared Small Target Detection in Complex Scenes
Mar 10, 2025



Infrared small target detection is currently a hot and challenging task in computer vision. Existing methods usually focus on mining visual features of targets, which struggles to cope with complex and diverse detection scenarios. The main reason is that infrared small targets have limited image information on their own, thus relying only on visual features fails to discriminate targets and interferences, leading to lower detection performance. To address this issue, we introduce a novel approach leveraging semantic text to guide infrared small target detection, called Text-IRSTD. It innovatively expands classical IRSTD to text-guided IRSTD, providing a new research idea. On the one hand, we devise a novel fuzzy semantic text prompt to accommodate ambiguous target categories. On the other hand, we propose a progressive cross-modal semantic interaction decoder (PCSID) to facilitate information fusion between texts and images. In addition, we construct a new benchmark consisting of 2,755 infrared images of different scenarios with fuzzy semantic textual annotations, called FZDT. Extensive experimental results demonstrate that our method achieves better detection performance and target contour recovery than the state-of-the-art methods. Moreover, proposed Text-IRSTD shows strong generalization and wide application prospects in unseen detection scenarios. The dataset and code will be publicly released after acceptance of this paper.
Legal Fact Prediction: Task Definition and Dataset Construction
Sep 11, 2024



Legal facts refer to the facts that can be proven by acknowledged evidence in a trial. They form the basis for the determination of court judgments. This paper introduces a novel NLP task: legal fact prediction, which aims to predict the legal fact based on a list of evidence. The predicted facts can instruct the parties and their lawyers involved in a trial to strengthen their submissions and optimize their strategies during the trial. Moreover, since real legal facts are difficult to obtain before the final judgment, the predicted facts also serve as an important basis for legal judgment prediction. We construct a benchmark dataset consisting of evidence lists and ground-truth legal facts for real civil loan cases, LFPLoan. Our experiments on this dataset show that this task is non-trivial and requires further considerable research efforts.
Shall We Talk: Exploring Spontaneous Collaborations of Competing LLM Agents
Feb 19, 2024



Recent advancements have shown that agents powered by large language models (LLMs) possess capabilities to simulate human behaviors and societal dynamics. However, the potential for LLM agents to spontaneously establish collaborative relationships in the absence of explicit instructions has not been studied. To address this gap, we conduct three case studies, revealing that LLM agents are capable of spontaneously forming collaborations even within competitive settings. This finding not only demonstrates the capacity of LLM agents to mimic competition and cooperation in human societies but also validates a promising vision of computational social science. Specifically, it suggests that LLM agents could be utilized to model human social interactions, including those with spontaneous collaborations, thus offering insights into social phenomena. The source codes for this study are available at https://github.com/wuzengqing001225/SABM_ShallWeTalk .
Smart Agent-Based Modeling: On the Use of Large Language Models in Computer Simulations
Nov 22, 2023



Computer simulations offer a robust toolset for exploring complex systems across various disciplines. A particularly impactful approach within this realm is Agent-Based Modeling (ABM), which harnesses the interactions of individual agents to emulate intricate system dynamics. ABM's strength lies in its bottom-up methodology, illuminating emergent phenomena by modeling the behaviors of individual components of a system. Yet, ABM has its own set of challenges, notably its struggle with modeling natural language instructions and common sense in mathematical equations or rules. This paper seeks to transcend these boundaries by integrating Large Language Models (LLMs) like GPT into ABM. This amalgamation gives birth to a novel framework, Smart Agent-Based Modeling (SABM). Building upon the concept of smart agents -- entities characterized by their intelligence, adaptability, and computation ability -- we explore in the direction of utilizing LLM-powered agents to simulate real-world scenarios with increased nuance and realism. In this comprehensive exploration, we elucidate the state of the art of ABM, introduce SABM's potential and methodology, and present three case studies (source codes available at https://github.com/Roihn/SABM), demonstrating the SABM methodology and validating its effectiveness in modeling real-world systems. Furthermore, we cast a vision towards several aspects of the future of SABM, anticipating a broader horizon for its applications. Through this endeavor, we aspire to redefine the boundaries of computer simulations, enabling a more profound understanding of complex systems.
Incentive Mechanism for Privacy-Preserving Federated Learning
Jun 08, 2021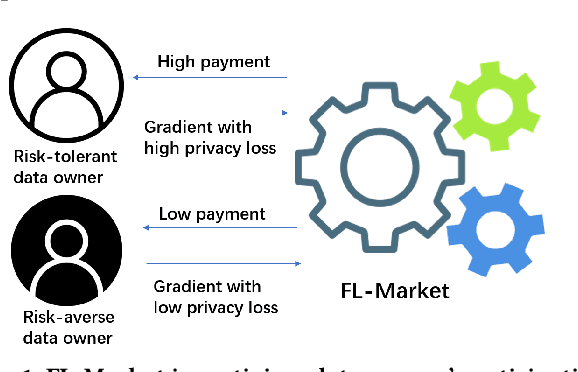
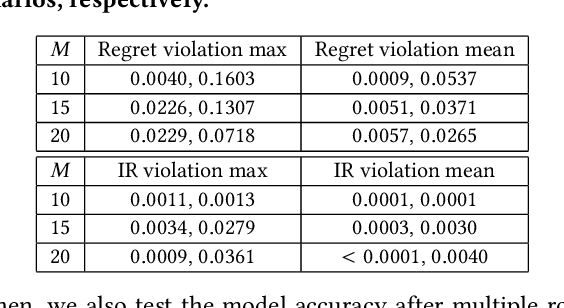
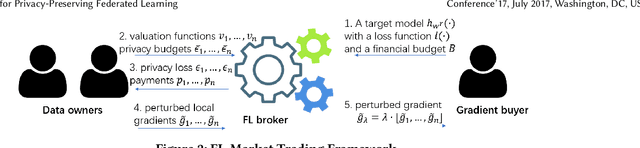
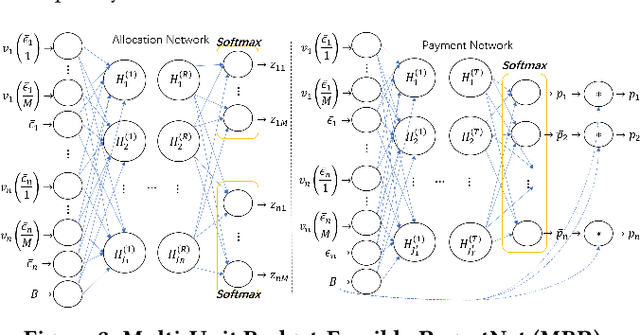
Federated learning (FL) is an emerging paradigm for machine learning, in which data owners can collaboratively train a model by sharing gradients instead of their raw data. Two fundamental research problems in FL are incentive mechanism and privacy protection. The former focuses on how to incentivize data owners to participate in FL. The latter studies how to protect data owners' privacy while maintaining high utility of trained models. However, incentive mechanism and privacy protection in FL have been studied separately and no work solves both problems at the same time. In this work, we address the two problems simultaneously by an FL-Market that incentivizes data owners' participation by providing appropriate payments and privacy protection. FL-Market enables data owners to obtain compensation according to their privacy loss quantified by local differential privacy (LDP). Our insight is that, by meeting data owners' personalized privacy preferences and providing appropriate payments, we can (1) incentivize privacy risk-tolerant data owners to set larger privacy parameters (i.e., gradients with less noise) and (2) provide preferred privacy protection for privacy risk-averse data owners. To achieve this, we design a personalized LDP-based FL framework with a deep learning-empowered auction mechanism for incentivizing trading gradients with less noise and optimal aggregation mechanisms for model updates. Our experiments verify the effectiveness of the proposed framework and mechanisms.